Abstract
Unsupervised reinforcement learning (URL) aims to pre-train agents by exploring diverse states or skills in reward-free environments, facilitating efficient adaptation to downstream tasks. As the agent cannot access extrinsic rewards during unsupervised exploration, existing methods design intrinsic rewards to model the explored data and encourage further exploration. However, the explored data are always heterogeneous, posing the requirements of powerful representation abilities for both intrinsic reward models and pre-trained policies. In this work, we propose the Exploratory Diffusion Model (ExDM), which leverages the strong expressive ability of diffusion models to fit the explored data, simultaneously boosting exploration and providing an efficient initialization for downstream tasks. Specifically, ExDM can accurately estimate the distribution of collected data in the replay buffer with the diffusion model and introduces the score-based intrinsic reward, encouraging the agent to explore less-visited states. After obtaining the pre-trained policies, ExDM enables rapid adaptation to downstream tasks. In detail, we provide theoretical analyses and practical algorithms for fine-tuning diffusion policies, addressing key challenges such as training instability and computational complexity caused by multi-step sampling. Extensive experiments demonstrate that ExDM outperforms existing SOTA baselines in efficient unsupervised exploration and fast fine-tuning downstream tasks, especially in structurally complicated environments.
ExDM Overview
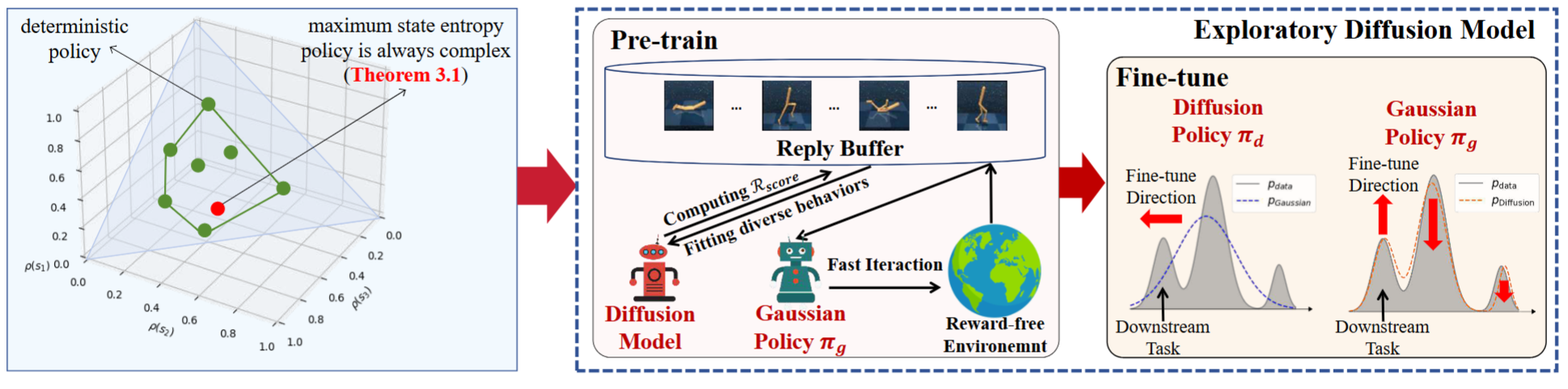
Overview of Exploratory Diffusion Model (ExDM). Different from standard RL, URL aims to explore in reward-free environments, requiring expressive policies and models to fit heterogeneous data. During pre-training, ExDM employs the diffusion model to model the heterogeneous exploration data and calculate score-based intrinsic rewards to encourage exploration. Moreover, we adopt a Gaussian behavior policy to collect data that avoids the inefficiency caused by the multi-step sampling of the diffusion policy.
Experiments
We consider extensive experimental setting, including Maze2d for evaluating unsupervised exploration and URLB for evaluating the few-shot fine-tuning.
Maze2d Results

Trajectories collected during unsupervised exploration stage in Maze2d.
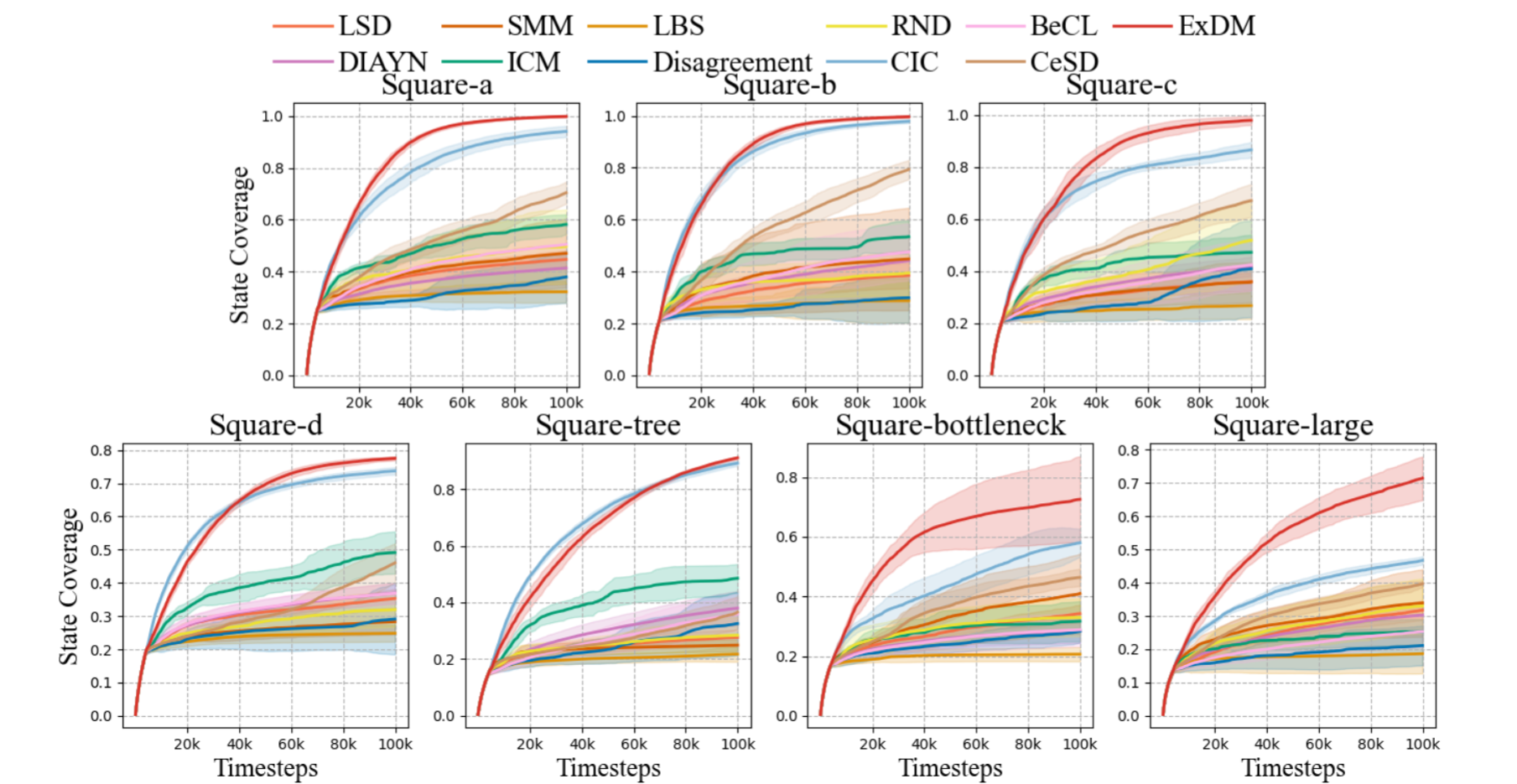
State coverage ratios during unsupervised exploration stage in Maze2d.
URLB Results
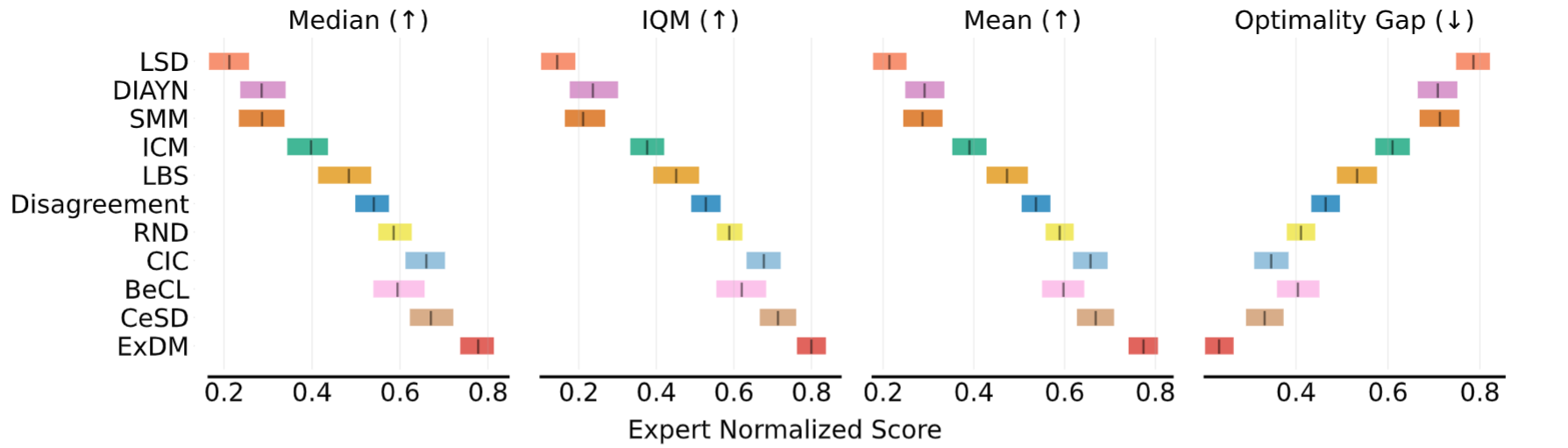
Performance of fine-tuning Gaussian policies in URLB.

Performance of fine-tuning diffusion policies in URLB.
BibTeX
@article{ying2025exploratory,
title={Exploratory Diffusion Policy for Unsupervised Reinforcement Learning},
author={Ying, Chengyang and Chen, Huayu and Zhou, Xinning and Hao, Zhongkai and Su, Hang and Zhu, Jun},
journal={arXiv preprint arXiv:2502.07279},
year={2025}
}